Chapter 8 Asking Business Questions From a Single Table
This chapter explores:
- Issues that come up when investigating a single table from a business perspective
- Show the multiple data anomalies found in a single AdventureWorks table (salesorderheader)
- The interplay between “data questions” and “business questions”
The previous chapter has demonstrated some of the automated techniques for showing what’s in a table using some standard R functions and packages. Now we demonstrate a step-by-step process of making sense of what’s in one table with more of a business perspective. We illustrate the kind of detective work that’s often involved as we investigate the organizational meaning of the data in a table. We’ll investigate the salesorderheader table in the sales schema in this example to understand the sales profile of the “AdventureWorks” business. We show that there are quite a few interpretation issues even when we are examining just 3 out of the 25 columns in one table.
For this kind of detective work we are seeking to understand the following elements separately and as they interact with each other:
- What data is stored in the database
- How information is represented
- How the data is entered at a day-to-day level to represent business activities
- How the business itself is changing over time
8.1 Setup our standard working environment
Use these libraries:
library(tidyverse)
library(DBI)
library(RPostgres)
library(connections)
library(glue)
require(knitr)
library(dbplyr)
library(sqlpetr)
library(bookdown)
library(here)
library(lubridate)
library(gt)
library(scales)
library(patchwork)
theme_set(theme_light())Connect to adventureworks. In an interactive session we prefer to use connections::connection_open instead of dbConnect
sp_docker_start("adventureworks")
Sys.sleep(sleep_default)
con <- dbConnect(
RPostgres::Postgres(),
# without the previous and next lines, some functions fail with bigint data
# so change int64 to integer
bigint = "integer",
host = "localhost",
port = 5432,
user = "postgres",
password = "postgres",
dbname = "adventureworks")Some queries generate big integers, so we need to include RPostgres::Postgres() and bigint = "integer" in the connections statement because some functions in the tidyverse object to the bigint datatype.
8.2 A word on naming
You will find that many tables will have columns with the same name in an enterprise database. For example, in the AdventureWorks database, almost all tables have columns named
rowguidandmodifieddateand there are many other examples of names that are reused throughout the database. Duplicate columns are best renamed or deliberately dropped. The meaning of a column depends on the table that contains it, so as you pull a column out of a table, when renaming it the collumns provenance should be reflected in the new name.Naming columns carefully (whether retrieved from the database or calculated) will pay off, especially as our queries become more complex. Using
sohas an abbreviation of sales order header to tag columns or statistics that are derived from thesalesorderheadertable, as we do in this book, is one example of an intentional naming strategy: it reminds us of the original source of the data. You, future you, and your collaborators will appreciate the effort no matter what naming convention you adopt. And a naming convention when rigidly applied can yield some long and ugly names.In the following example
sohappears in different positions in the column name but it is easy to guess at a glance that the data comes from thesalesorderheadertable.Naming derived tables is just as important as naming derived columns.
8.3 The overall AdventureWorks sales picture
We begin by looking at Sales on a yearly basis, then consider monthly sales. We discover that half way through the period represented in the database, the business appears to begin selling online, which has very different characteristics than sales by Sales Reps. We then look at the details of how Sales Rep sales are recorded in the system and discover a data anomaly that we can correct.
8.4 Annual sales
On an annual basis, are sales dollars trending up, down or flat? We begin with annual revenue and number of orders.
annual_sales <- tbl(con, in_schema("sales", "salesorderheader")) %>%
mutate(year = substr(as.character(orderdate), 1, 4)) %>%
group_by(year) %>%
summarize(
min_soh_orderdate = min(orderdate, na.rm = TRUE),
max_soh_orderdate = max(orderdate, na.rm = TRUE),
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
avg_total_soh_dollars = round(mean(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
arrange(year) %>%
select(
year, min_soh_orderdate, max_soh_orderdate, total_soh_dollars,
avg_total_soh_dollars, soh_count
) %>%
collect() Note that all of this query is running on the server since the collect() statement is at the very end.
## Classes 'tbl_df', 'tbl' and 'data.frame': 4 obs. of 6 variables:
## $ year : chr "2011" "2012" "2013" "2014"
## $ min_soh_orderdate : POSIXct, format: "2011-05-31" "2012-01-01" ...
## $ max_soh_orderdate : POSIXct, format: "2011-12-31" "2012-12-31" ...
## $ total_soh_dollars : num 12641672 33524301 43622479 20057929
## $ avg_total_soh_dollars: num 7867 8563 3076 1705
## $ soh_count : int 1607 3915 14182 11761We hang on to some date information for later use in plot titles.
8.4.1 Annual summary of sales, number of transactions and average sale
tot_sales <- ggplot(data = annual_sales, aes(x = year, y = total_soh_dollars/100000)) +
geom_col() +
geom_text(aes(label = round(as.numeric(total_soh_dollars/100000), digits = 0)), vjust = 1.5, color = "white") +
scale_y_continuous(labels = scales::dollar_format()) +
labs(
title = "Total Sales per Year - Millions",
x = NULL,
y = "Sales $M"
)Both 2011 and 2014 turn out to be are shorter time spans than the other two years, making comparison interpretation difficult. Still, it’s clear that 2013 was the best year for annual sales dollars.
Comparing the number of orders per year has roughly the same overall pattern (2013 ranks highest, etc.) but the proportions between the years are quite different.
Although 2013 was the best year in terms of total number of orders, there were many more in 2014 compared with 2012. That suggests looking at the average dollars per sale for each year.
8.4.2 Average dollars per sale
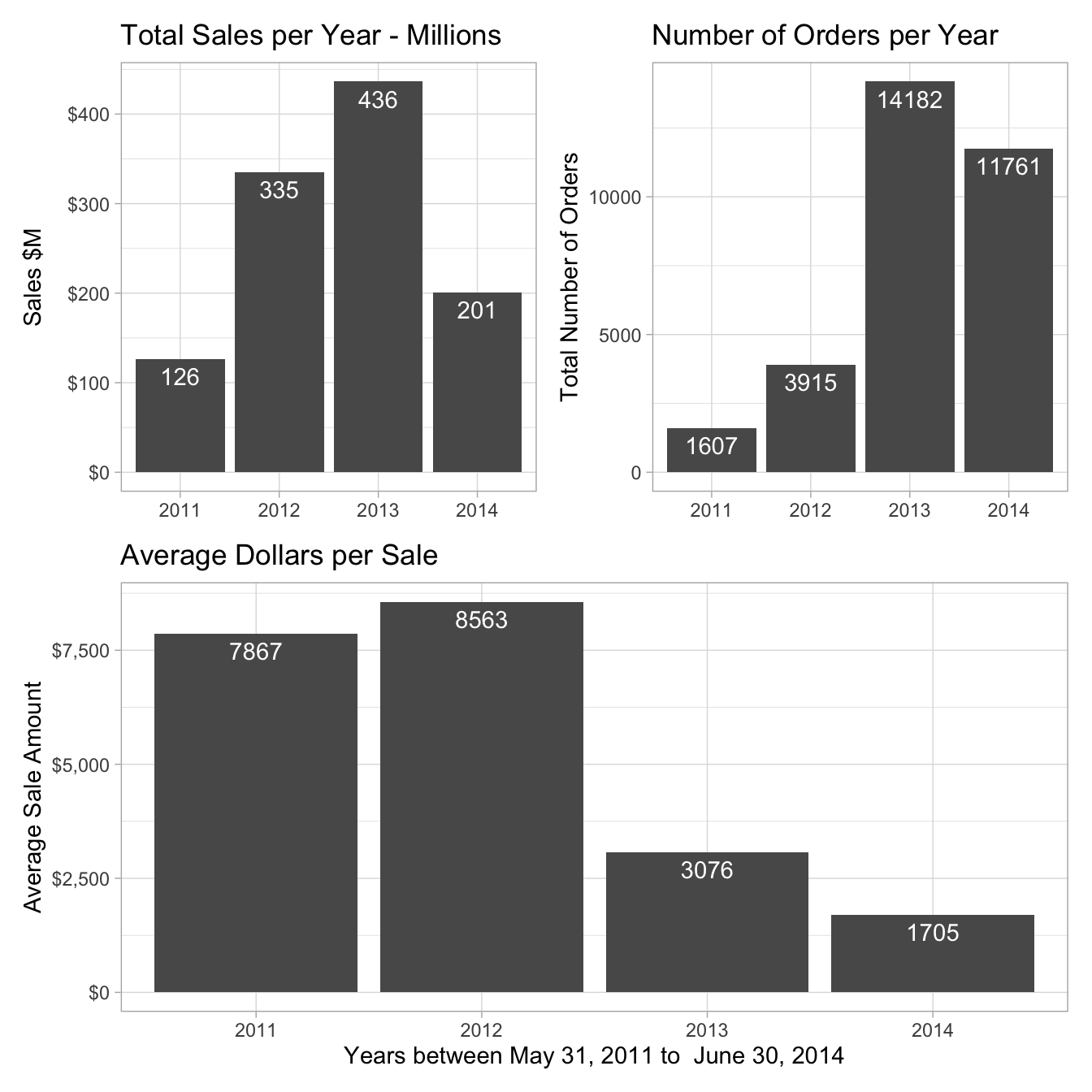
Figure 8.1: AdventureWorks sales performance
That’s a big drop between average sale of more than $7,000 in the first two years down to the $3,000 range in the last two. There has been a remarkable change in this business. At the same time the total number of orders shot up from less than 4,000 a year to more than 14,000. Why are the number of orders increasing, but the average dollar amount of a sale is dropping?
Perhaps monthly monthly sales has the answer. We adapt the first query to group by month and year.
8.5 Monthly Sales
Our next iteration drills down from annual sales dollars to monthly sales dollars. For that we download the orderdate as a date, rather than a character variable for the year. R handles the conversion from the PostgreSQL date-time to an R date-time. We then convert it to a simple date with a lubridate function.
The following query uses the postgreSQL function date_trunc, which is equivalent to lubridate’s round_date function in R. If you want to push as much of the processing as possible onto the database server and thus possibly deal with smaller datasets in R, interleaving postgreSQL functions into your dplyr code will help.
monthly_sales <- tbl(con, in_schema("sales", "salesorderheader")) %>%
select(orderdate, subtotal) %>%
mutate(
orderdate = date_trunc('month', orderdate)
) %>%
group_by(orderdate) %>%
summarize(
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
avg_total_soh_dollars = round(mean(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
show_query() %>%
collect() ## <SQL>
## SELECT "orderdate", ROUND((SUM("subtotal")) :: numeric, 2) AS "total_soh_dollars", ROUND((AVG("subtotal")) :: numeric, 2) AS "avg_total_soh_dollars", COUNT(*) AS "soh_count"
## FROM (SELECT date_trunc('month', "orderdate") AS "orderdate", "subtotal"
## FROM sales.salesorderheader) "dbplyr_004"
## GROUP BY "orderdate"Note that
date_trunc('month', orderdate)gets passed through exactly “as is.”
In many cases we don’t really care whether our queries are executed by R or by the SQL server, but if we do care we need to substitute the postgreSQL equivalent for the R functions we might ordinarily use. In those cases we have to check whether functions from R packages like lubridate and the equivalent postgreSQL functions are exactly alike. Often they are subtly different: in the previous query the postgreSQL function produces a POSIXct column, not a Date so we need to tack on a mutate function once the data is on the R side as shown here:
Next let’s plot the monthly sales data:
ggplot(data = monthly_sales, aes(x = orderdate, y = total_soh_dollars)) +
geom_col() +
scale_y_continuous(labels = dollar) +
theme(plot.title = element_text(hjust = 0.5)) +
labs(
title = glue("Sales by Month\n", {format(min_soh_dt, "%B %d, %Y")} , " to ",
{format(max_soh_dt, "%B %d, %Y")}),
x = "Month",
y = "Sales Dollars"
)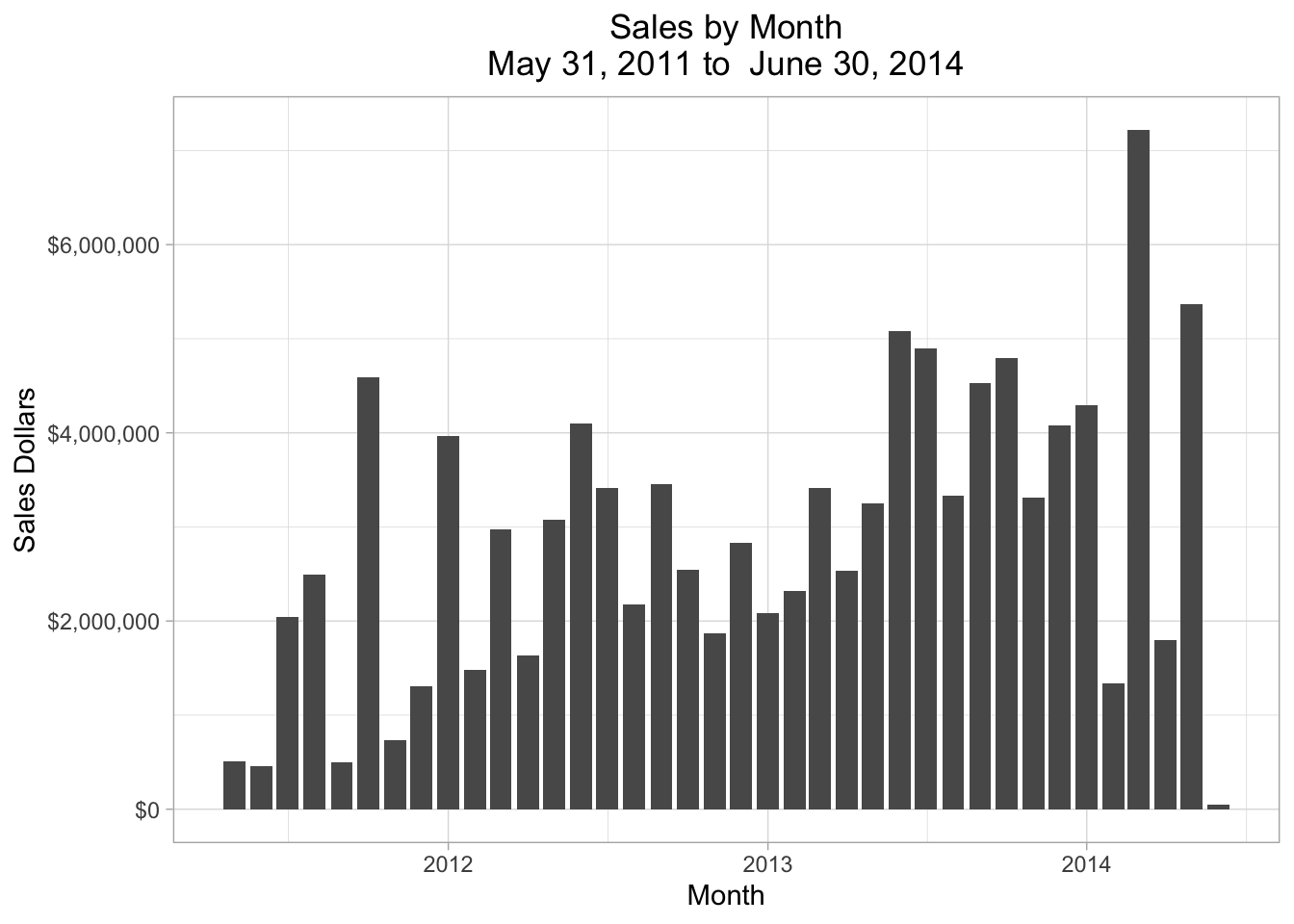
Figure 8.2: Total Monthly Sales
That graph doesn’t show how the business might have changed, but it is remarkable how much variation there is from one month to another – particularly in 2012 and 2014.
8.5.1 Check lagged monthly data
Because of the month-over-month sales variation. We’ll use dplyr::lag to help find the delta and later visualize just how much month-to-month difference there is.
monthly_sales <- arrange(monthly_sales, orderdate)
monthly_sales_lagged <- monthly_sales %>%
mutate(monthly_sales_change = (dplyr::lag(total_soh_dollars)) - total_soh_dollars)
monthly_sales_lagged[is.na(monthly_sales_lagged)] = 0## [1] -221690.505## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -5879806.05 -1172995.19 -221690.51 11968.42 1159252.70 5420357.17The average month over month change in sales looks OK ($ 11,968) although the Median is negative: $ 11,968. There is a very wide spread in our month-over-month sales data between the lower and upper quartile. We can plot the variation as follows:
ggplot(monthly_sales_lagged, aes(x = orderdate, y = monthly_sales_change)) +
scale_x_date(date_breaks = "year", date_labels = "%Y", date_minor_breaks = "3 months") +
geom_line() +
# geom_point() +
scale_y_continuous(limits = c(-6000000,5500000), labels = scales::dollar_format()) +
theme(plot.title = element_text(hjust = .5)) +
labs(
title = glue(
"Monthly Sales Change \n",
"Between ", {format(min_soh_dt, "%B %d, %Y")} , " and ",
{format(max_soh_dt, "%B %d, %Y")}
),
x = "Month",
y = "Dollar Change"
)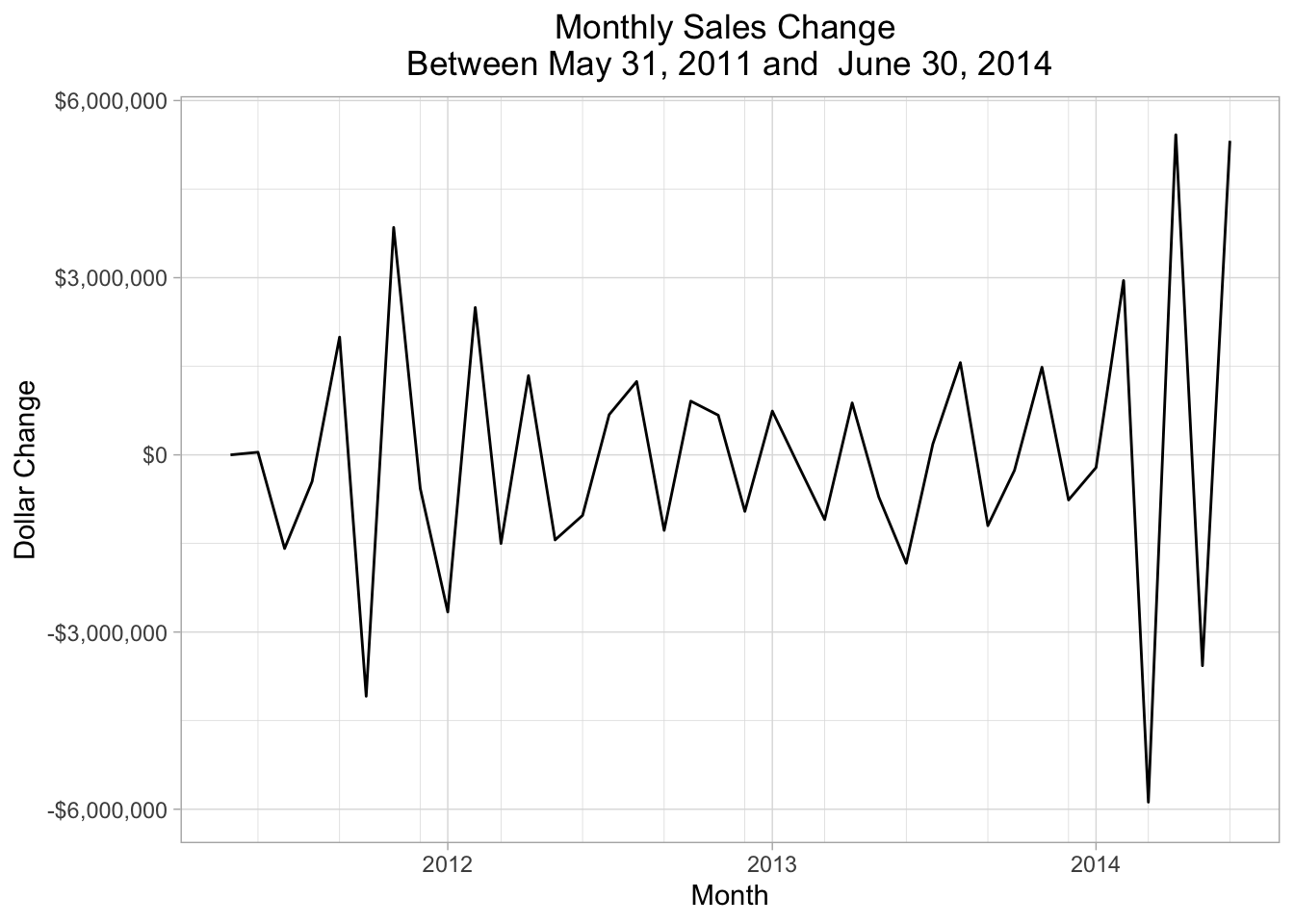
Figure 8.3: Monthly Sales Change
It looks like the big change in the business occurred in the summer of 2013 when the number of orders jumped but the dollar volume just continued to bump along.
8.5.2 Comparing dollars and orders to a base year
To look at dollars and the number of orders together, we compare the monthly data to the yearly average for 2011.
baseline_month <- "2011-07-01"
start_month <- monthly_sales %>%
filter(orderdate == as.Date(baseline_month))Express monthly data relative to 2011-07-01, 2044600, 8851.08, 231
monthly_sales_base_year_normalized_to_2011 <- monthly_sales %>%
mutate(
dollars = (100 * total_soh_dollars) / start_month$total_soh_dollars,
number_of_orders = (100 * soh_count) / start_month$soh_count
) %>%
ungroup()
monthly_sales_base_year_normalized_to_2011 <- monthly_sales_base_year_normalized_to_2011 %>%
select(orderdate, dollars, `# of orders` = number_of_orders) %>%
pivot_longer(-orderdate,
names_to = "relative_to_2011_average",
values_to = "amount"
)monthly_sales_base_year_normalized_to_2011 %>%
ggplot(aes(orderdate, amount, color = relative_to_2011_average)) +
geom_line() +
geom_hline(yintercept = 100) +
scale_x_date(date_labels = "%Y-%m", date_breaks = "6 months") +
labs(
title = glue(
"Adventureworks Normalized Monthly Sales\n",
"Number of Sales Orders and Dollar Totals\n",
{format(min_soh_dt, "%B %d, %Y")} , " to ",
{format(max_soh_dt, "%B %d, %Y")}),
x = "Date",
y = "",
color = glue(baseline_month, " values = 100")
) +
theme(legend.position = c(.3,.75))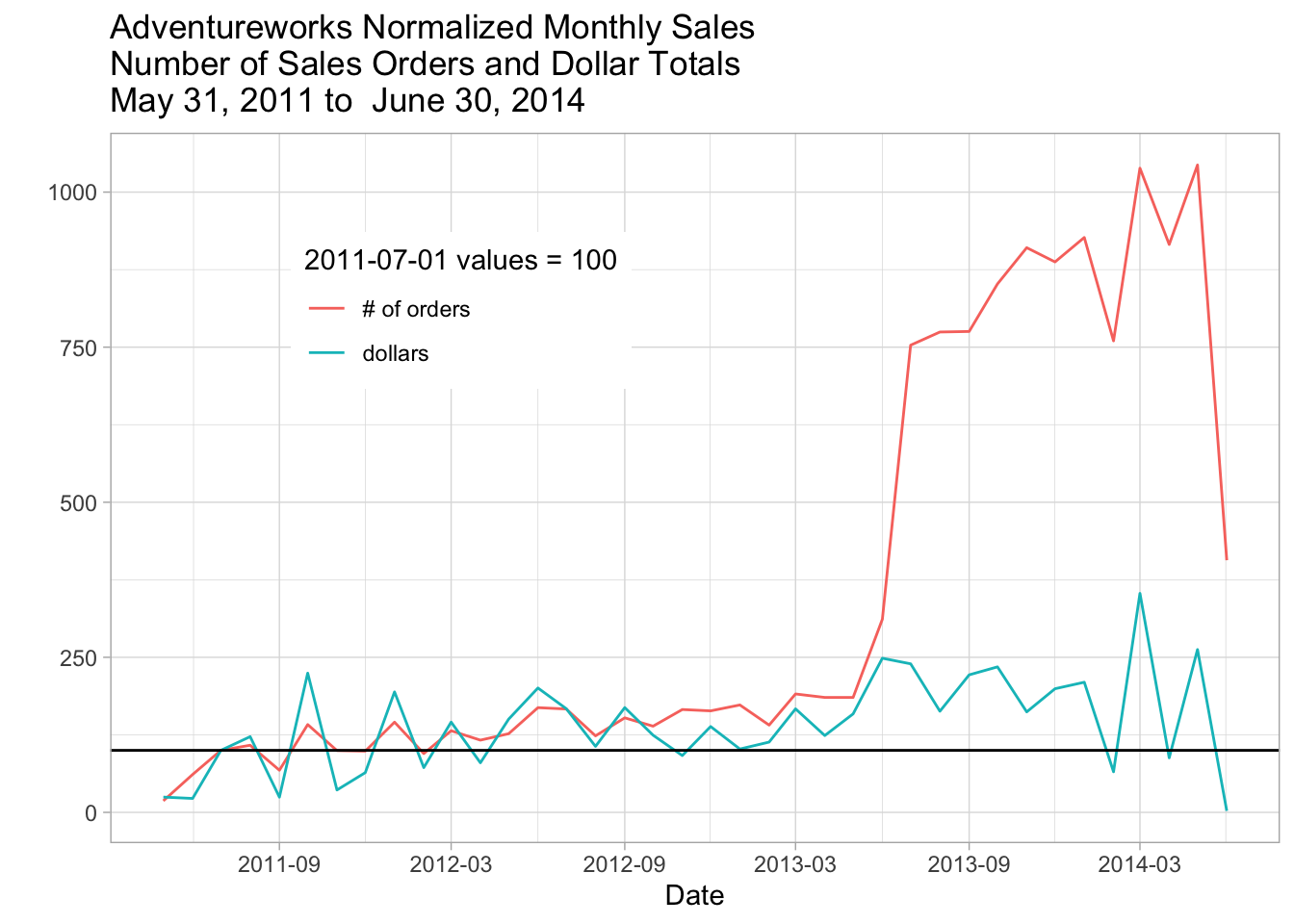
Figure 8.4: Adventureworks Normalized Monthly Sales
8.6 The effect of online sales
We suspect that the business has changed a lot with the advent of online orders so we check the impact of onlineorderflag on annual sales. The onlineorderflag indicates which sales channel accounted for the sale, Sales Reps or Online.
8.6.1 Add onlineorderflag to our annual sales query
annual_sales_w_channel <- tbl(con, in_schema("sales", "salesorderheader")) %>%
select(orderdate, subtotal, onlineorderflag) %>%
collect() %>%
mutate(
orderdate = date(orderdate),
orderdate = round_date(orderdate, "month"),
onlineorderflag = if_else(onlineorderflag == FALSE,
"Sales Rep", "Online"
),
onlineorderflag = as.factor(onlineorderflag)
) %>%
group_by(orderdate, onlineorderflag) %>%
summarize(
min_soh_orderdate = min(orderdate, na.rm = TRUE),
max_soh_orderdate = max(orderdate, na.rm = TRUE),
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
avg_total_soh_dollars = round(mean(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
select(
orderdate, onlineorderflag, min_soh_orderdate,
max_soh_orderdate, total_soh_dollars,
avg_total_soh_dollars, soh_count
)Note that we are creating a factor and doing most of the calculations on the R side, not on the DBMS side.
8.6.2 Annual Sales comparison
Start by looking at total sales.
ggplot(data = annual_sales_w_channel, aes(x = orderdate, y = total_soh_dollars)) +
geom_col() +
scale_y_continuous(labels = scales::dollar_format()) +
facet_wrap("onlineorderflag") +
labs(
title = "AdventureWorks Monthly Sales",
caption = glue( "Between ", {format(min_soh_dt, "%B %d, %Y")} , " - ",
{format(max_soh_dt, "%B %d, %Y")}),
subtitle = "Comparing Online and Sales Rep sales channels",
x = "Year",
y = "Sales $"
)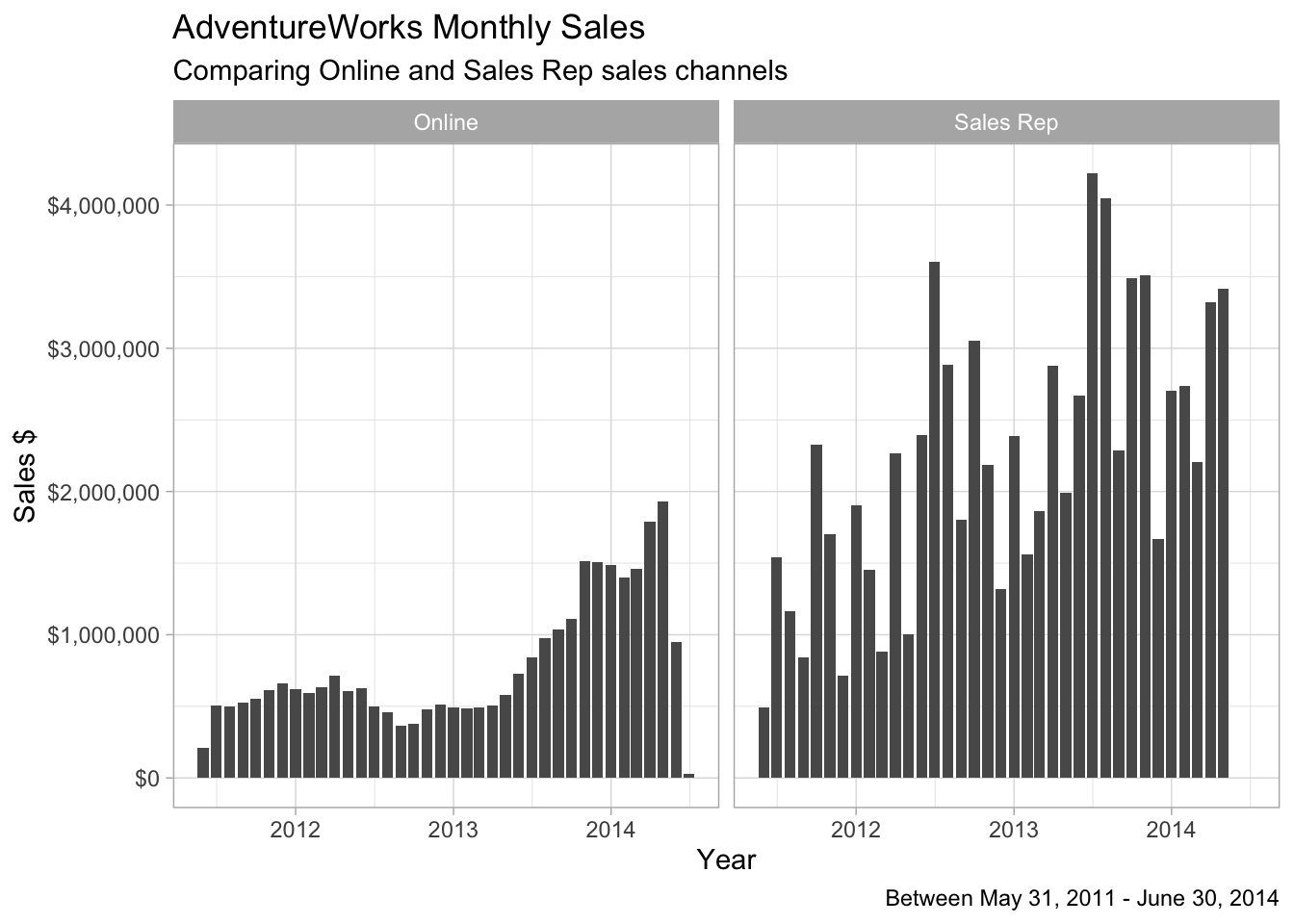
(#fig:Calculate annual sales dollars )Sales Channel Breakdown
It looks like there are two businesses represented in the AdventureWorks database that have very different growth profiles.
8.6.3 Order volume comparison
ggplot(data = annual_sales_w_channel, aes(x = orderdate, y = as.numeric(soh_count))) +
geom_col() +
facet_wrap("onlineorderflag") +
labs(
title = "AdventureWorks Monthly orders",
caption = glue( "Between ", {format(min_soh_dt, "%B %d, %Y")} , " - ",
{format(max_soh_dt, "%B %d, %Y")}),
subtitle = "Comparing Online and Sales Rep sales channels",
x = "Year",
y = "Total number of orders"
)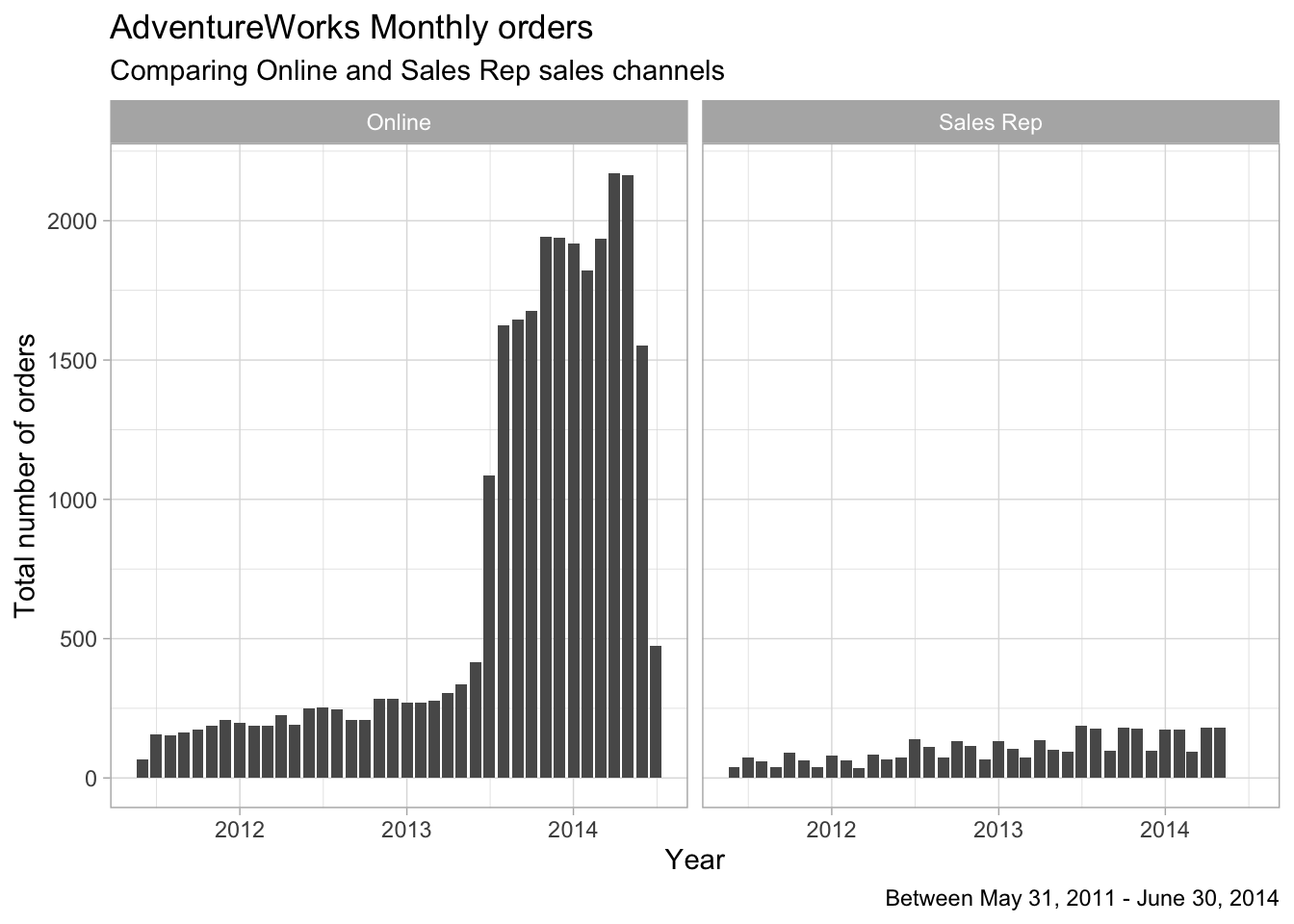
Figure 8.5: AdventureWorks Monthly Orders by Channel
Comparing Online and Sales Rep sales, the difference in the number of orders is even more striking than the difference between annual sales.
8.6.4 Comparing average order size: Sales Reps to Online orders
ggplot(data = annual_sales_w_channel, aes(x = orderdate, y = avg_total_soh_dollars)) +
geom_col() +
facet_wrap("onlineorderflag") +
scale_y_continuous(labels = scales::dollar_format()) +
labs(
title = "AdventureWorks Average Dollars per Sale",
x = glue( "Year - between ", {format(min_soh_dt, "%B %d, %Y")} , " - ",
{format(max_soh_dt, "%B %d, %Y")}),
y = "Average sale amount"
)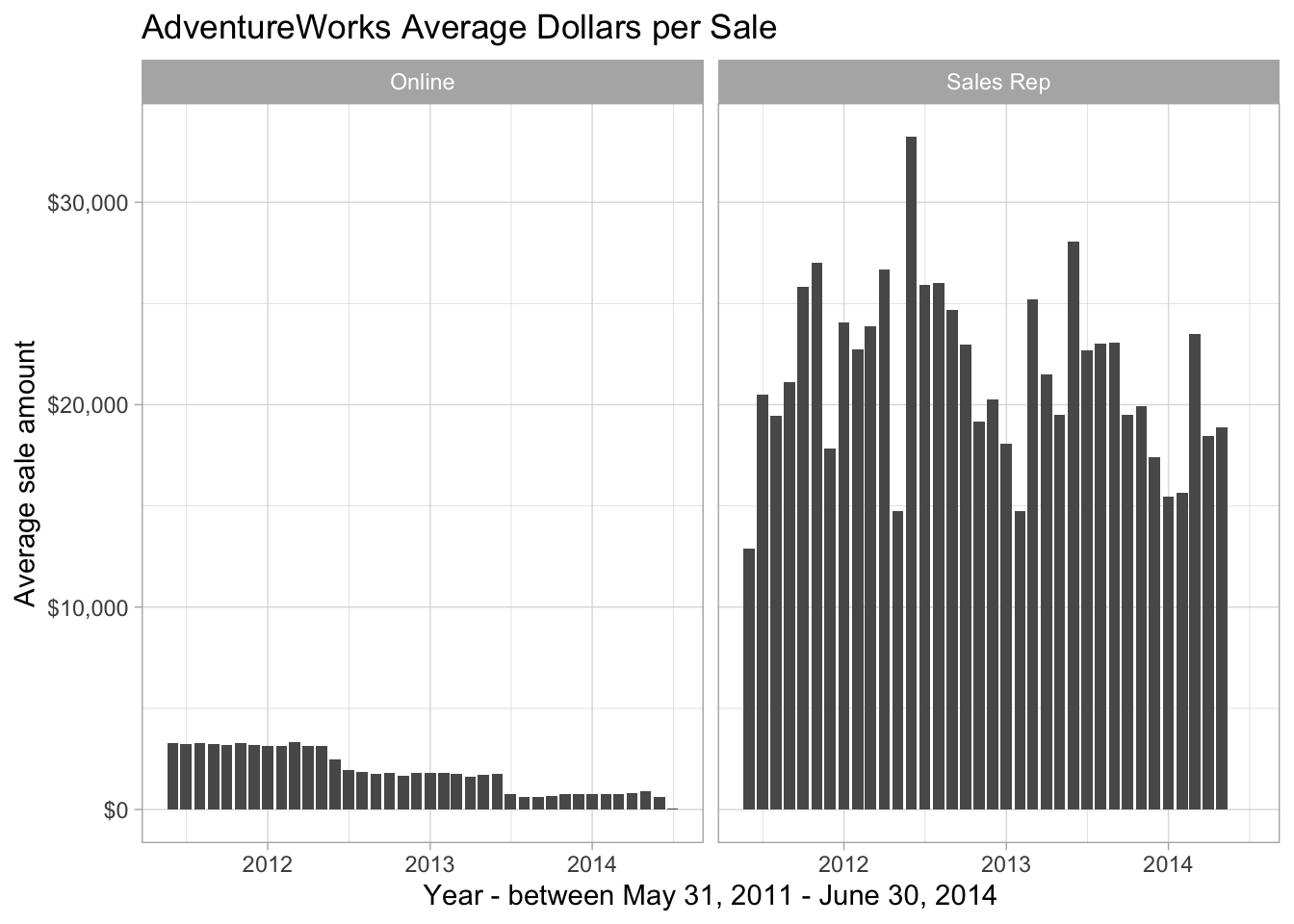
Figure 8.6: Average dollar per Sale comparison
8.7 Impact of order type on monthly sales
To dig into the difference between Sales Rep and Online sales we can look at monthly data.
8.7.1 Retrieve monthly sales with the onlineorderflag
This query puts the collect statement earlier than the previous queries.
monthly_sales_w_channel <- tbl(con, in_schema("sales", "salesorderheader")) %>%
select(orderdate, subtotal, onlineorderflag) %>%
collect() %>% # From here on we're in R
mutate(
orderdate = date(orderdate),
orderdate = floor_date(orderdate, unit = "month"),
onlineorderflag = if_else(onlineorderflag == FALSE,
"Sales Rep", "Online")
) %>%
group_by(orderdate, onlineorderflag) %>%
summarize(
min_soh_orderdate = min(orderdate, na.rm = TRUE),
max_soh_orderdate = max(orderdate, na.rm = TRUE),
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
avg_total_soh_dollars = round(mean(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
ungroup()monthly_sales_w_channel %>%
rename(`Sales Channel` = onlineorderflag) %>%
group_by(`Sales Channel`) %>%
summarize(
unique_dates = n(),
start_date = min(min_soh_orderdate),
end_date = max(max_soh_orderdate),
total_sales = round(sum(total_soh_dollars)),
days_span = end_date - start_date
) %>%
gt()| Sales Channel | unique_dates | start_date | end_date | total_sales | days_span |
|---|---|---|---|---|---|
| Online | 38 | 2011-05-01 | 2014-06-01 | 29358677 | 1127 days |
| Sales Rep | 34 | 2011-05-01 | 2014-05-01 | 80487704 | 1096 days |
As this table shows, the Sales Rep dates don’t match the Online dates. They start on the same date, but have a different end. The Online dates include 2 months that are not included in the Sales Rep sales (which are the main sales channel by dollar volume).
8.7.2 Monthly variation compared to a trend line
Jumping to the trend line comparison, we see that the big the source of variation is on the Sales Rep side.
ggplot(
data = monthly_sales_w_channel,
aes(
x = orderdate, y = total_soh_dollars
)
) +
geom_line() +
geom_smooth(se = FALSE) +
facet_grid("onlineorderflag", scales = "free") +
scale_y_continuous(labels = dollar) +
scale_x_date(date_breaks = "year", date_labels = "%Y", date_minor_breaks = "3 months") +
theme(plot.title = element_text(hjust = .5)) + # Center ggplot title
labs(
title = glue(
"AdventureWorks Monthly Sales Trend"
),
x = glue( "Month - between ", {format(min_soh_dt, "%B %d, %Y")} , " - ",
{format(max_soh_dt, "%B %d, %Y")}),
y = "Sales Dollars"
)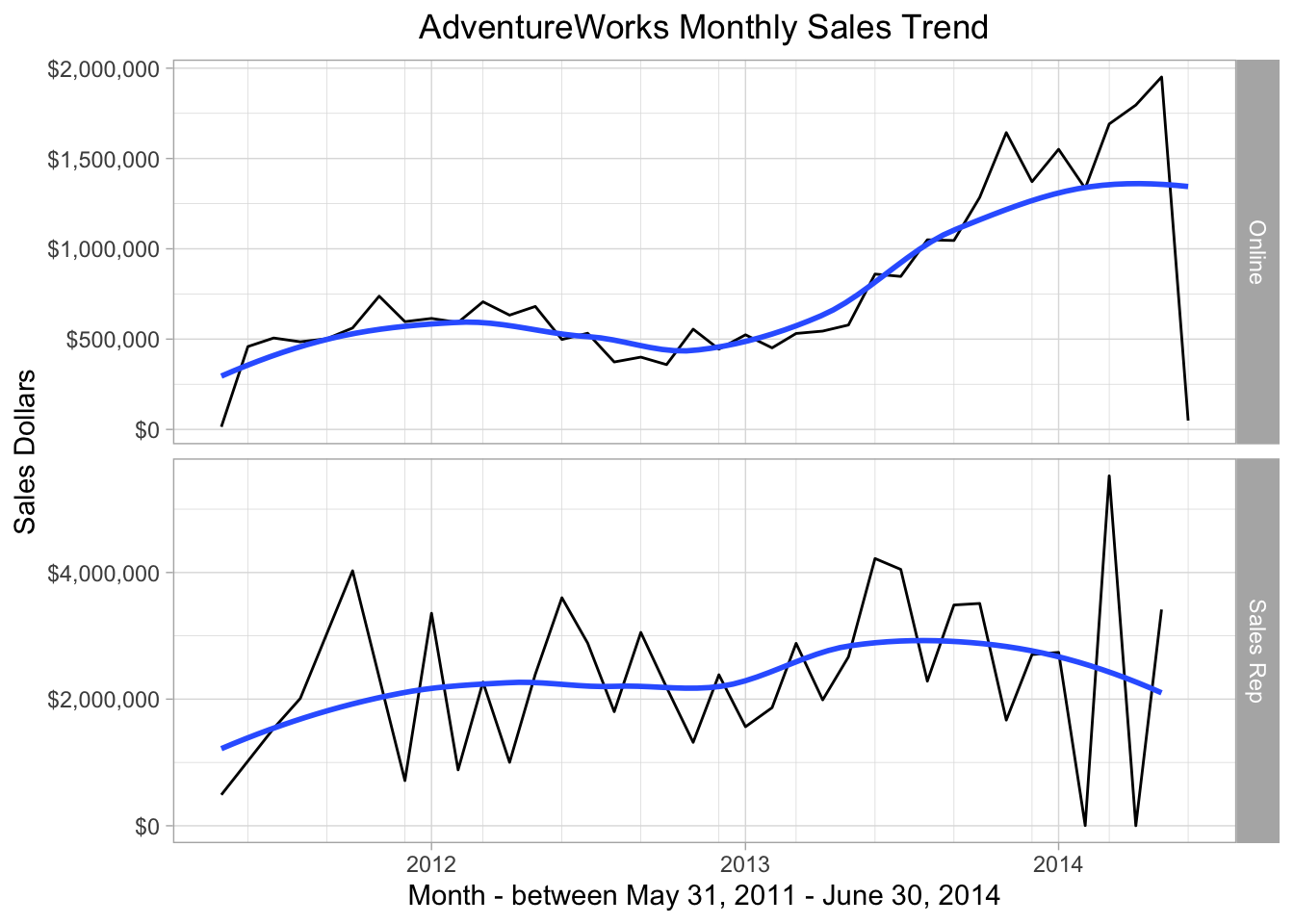
Figure 8.7: Monthly Sales Trend
The monthly gyrations are much larger on the Sales Rep side, amounting to differences in a million dollars compared to small monthly variations of around $25,000 for the Online orders.
8.7.3 Compare monthly lagged data by Sales Channel
First consider month-to-month change.
monthly_sales_w_channel_lagged_by_month <- monthly_sales_w_channel %>%
group_by(onlineorderflag) %>%
mutate(
lag_soh_count = lag(soh_count, 1),
lag_soh_total_dollars = lag(total_soh_dollars, 1),
pct_monthly_soh_dollar_change =
(total_soh_dollars - lag_soh_total_dollars) / lag_soh_total_dollars * 100,
pct_monthly_soh_count_change =
(soh_count - lag_soh_count) / lag_soh_count * 100
)The following table shows some wild changes in dollar amounts and number of sales from one month to the next.
monthly_sales_w_channel_lagged_by_month %>%
filter(abs(pct_monthly_soh_count_change) > 150 |
abs(pct_monthly_soh_dollar_change) > 150 ) %>%
ungroup() %>%
arrange(onlineorderflag, orderdate) %>%
mutate(
total_soh_dollars = round(total_soh_dollars),
lag_soh_total_dollars = round(lag_soh_total_dollars),
pct_monthly_soh_dollar_change = round(pct_monthly_soh_dollar_change),
pct_monthly_soh_count_change = round(pct_monthly_soh_count_change)) %>%
select(orderdate, onlineorderflag, total_soh_dollars, lag_soh_total_dollars,
soh_count, lag_soh_count, pct_monthly_soh_dollar_change, pct_monthly_soh_count_change) %>%
# names()
gt() %>%
fmt_number(
columns = c(3:4), decimals = 0) %>%
fmt_percent(
columns = c(7:8), decimals = 0) %>%
cols_label(
onlineorderflag = "Channel",
total_soh_dollars = "$ this Month",
lag_soh_total_dollars = "$ last Month",
soh_count = "# this Month",
lag_soh_count = "# last Month",
pct_monthly_soh_dollar_change = "$ change",
pct_monthly_soh_count_change = "# change"
)| orderdate | Channel | $ this Month | $ last Month | # this Month | # last Month | $ change | # change |
|---|---|---|---|---|---|---|---|
| 2011-06-01 | Online | 458,911 | 14,477 | 141 | 5 | 307,000% | 272,000% |
| 2013-07-01 | Online | 847,139 | 860,141 | 1564 | 533 | −200% | 19,300% |
| 2011-07-01 | Sales Rep | 1,538,408 | 489,329 | 75 | 38 | 21,400% | 9,700% |
| 2012-01-01 | Sales Rep | 3,356,069 | 713,117 | 143 | 40 | 37,100% | 25,800% |
| 2012-03-01 | Sales Rep | 2,269,117 | 882,900 | 85 | 37 | 15,700% | 13,000% |
| 2014-03-01 | Sales Rep | 5,526,352 | 3,231 | 271 | 3 | 17,096,000% | 893,300% |
| 2014-05-01 | Sales Rep | 3,415,479 | 1,285 | 179 | 2 | 26,573,900% | 885,000% |
We suspect that the business has changed a lot with the advent of Online orders.
8.8 Detect and diagnose the day of the month problem
There have been several indications that Sales Rep sales are recorded once a month while Online sales are recorded on a daily basis.
8.8.1 Sales Rep Orderdate Distribution
Look at the dates when sales are entered for sales by Sales Reps. The following query / plot combination shows this pattern. and the exception for transactions entered on the first day of the month.
tbl(con, in_schema("sales", "salesorderheader")) %>%
filter(onlineorderflag == FALSE) %>% # Drop online orders
mutate(orderday = day(orderdate)) %>%
count(orderday, name = "Orders") %>%
collect() %>%
full_join(tibble(orderday = seq(1:31))) %>%
mutate(orderday = as.factor(orderday)) %>%
ggplot(aes(orderday, Orders)) +
geom_col() +
coord_flip() +
labs(title = "The first day of the month looks odd",
x = "Day Number")## Joining, by = "orderday"## Warning: Removed 26 rows containing missing values (position_stack).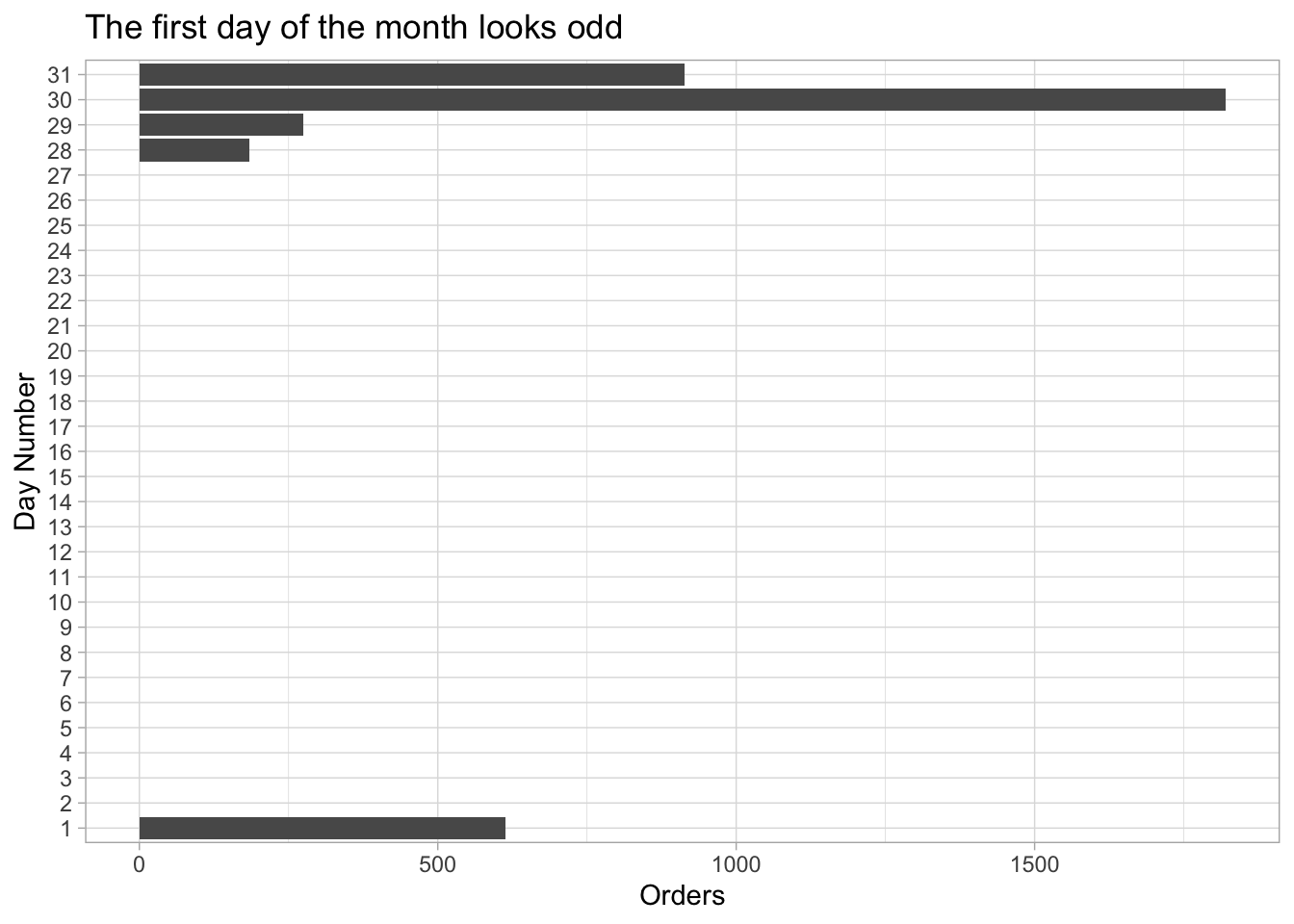
Figure 8.8: Days of the month with Sales Rep activity recorded
We can check on which months have orders entered on the first of the month.
sales_rep_day_of_month_sales <- tbl(con, in_schema("sales", "salesorderheader")) %>%
filter(onlineorderflag == FALSE) %>% # Drop online orders
select(orderdate, subtotal) %>%
mutate(
year = year(orderdate),
month = month(orderdate),
day = day(orderdate)
) %>%
count(year, month, day) %>%
collect() %>%
pivot_wider(names_from = day, values_from = n, names_prefix = "day_", values_fill = list(day_1 = 0, day_28 = 0, day_29 = 0, day_30 = 0, day_31 = 0) ) %>%
as.data.frame() %>%
select(year, month, day_1, day_28, day_29, day_30, day_31) %>%
filter(day_1 > 0) %>%
arrange(year, month)
sales_rep_day_of_month_sales## year month day_1 day_28 day_29 day_30 day_31
## 1 2011 7 75 NA NA NA NA
## 2 2011 8 60 NA NA NA 40
## 3 2011 10 90 NA NA NA 63
## 4 2011 12 40 NA NA NA NA
## 5 2012 1 79 NA 64 NA NA
## 6 2014 3 91 NA NA 2 178
## 7 2014 5 179 NA NA NA NAThere are two months with multiple sales rep order days for 2011, (11/08 and 11/10), one for 2012, (1201), and two in 2014, (14/01 and 14/03). The 14/03 is the only three day sales rep order month.
Are there months where there were no sales recorded for the sales reps?
There are two approaches. The first is to generate a list of months between the beginning and end of history and compare that to the Sales Rep records
monthly_sales_rep_sales <- monthly_sales_w_channel %>%
filter(onlineorderflag == "Sales Rep") %>%
mutate(orderdate = as.Date(floor_date(orderdate, "month"))) %>%
count(orderdate)
str(monthly_sales_rep_sales)## Classes 'tbl_df', 'tbl' and 'data.frame': 34 obs. of 2 variables:
## $ orderdate: Date, format: "2011-05-01" "2011-07-01" ...
## $ n : int 1 1 1 1 1 1 1 1 1 1 ...date_list <- tibble(month_date = seq.Date(floor_date(as.Date(min_soh_dt), "month"),
floor_date(as.Date(max_soh_dt), "month"),
by = "month"),
date_exists = FALSE)
date_list %>%
anti_join(monthly_sales_rep_sales,
by = c("month_date" = "orderdate") )## # A tibble: 4 x 2
## month_date date_exists
## <date> <lgl>
## 1 2011-06-01 FALSE
## 2 2011-09-01 FALSE
## 3 2011-11-01 FALSE
## 4 2014-06-01 FALSE- June, September, and November are missing for 2011.
- June for 2014
The second approach is to use the dates found in the database for online orders. Defining “complete” may not always be as simple as generating a complete list of months.
sales_order_header_online <- tbl(con, in_schema("sales", "salesorderheader")) %>%
filter(onlineorderflag == TRUE) %>%
mutate(
orderdate = date_trunc('month', orderdate)
) %>%
count(orderdate, name = "online_count")
sales_order_header_sales_rep <- tbl(con, in_schema("sales", "salesorderheader")) %>%
filter(onlineorderflag == FALSE) %>%
mutate(
orderdate = date_trunc('month', orderdate)
) %>%
count(orderdate, name = "sales_rep_count")
missing_dates <- sales_order_header_sales_rep %>%
full_join(sales_order_header_online) %>%
show_query() %>%
collect()## Joining, by = "orderdate"## <SQL>
## SELECT COALESCE("LHS"."orderdate", "RHS"."orderdate") AS "orderdate", "LHS"."sales_rep_count" AS "sales_rep_count", "RHS"."online_count" AS "online_count"
## FROM (SELECT "orderdate", COUNT(*) AS "sales_rep_count"
## FROM (SELECT "salesorderid", "revisionnumber", date_trunc('month', "orderdate") AS "orderdate", "duedate", "shipdate", "status", "onlineorderflag", "purchaseordernumber", "accountnumber", "customerid", "salespersonid", "territoryid", "billtoaddressid", "shiptoaddressid", "shipmethodid", "creditcardid", "creditcardapprovalcode", "currencyrateid", "subtotal", "taxamt", "freight", "totaldue", "comment", "rowguid", "modifieddate"
## FROM (SELECT *
## FROM sales.salesorderheader
## WHERE ("onlineorderflag" = FALSE)) "dbplyr_010") "dbplyr_011"
## GROUP BY "orderdate") "LHS"
## FULL JOIN (SELECT "orderdate", COUNT(*) AS "online_count"
## FROM (SELECT "salesorderid", "revisionnumber", date_trunc('month', "orderdate") AS "orderdate", "duedate", "shipdate", "status", "onlineorderflag", "purchaseordernumber", "accountnumber", "customerid", "salespersonid", "territoryid", "billtoaddressid", "shiptoaddressid", "shipmethodid", "creditcardid", "creditcardapprovalcode", "currencyrateid", "subtotal", "taxamt", "freight", "totaldue", "comment", "rowguid", "modifieddate"
## FROM (SELECT *
## FROM sales.salesorderheader
## WHERE ("onlineorderflag" = TRUE)) "dbplyr_012") "dbplyr_013"
## GROUP BY "orderdate") "RHS"
## ON ("LHS"."orderdate" = "RHS"."orderdate")missing_dates <- sales_order_header_online %>%
anti_join(sales_order_header_sales_rep) %>%
arrange(orderdate) %>%
collect()## Joining, by = "orderdate"## # A tibble: 4 x 2
## orderdate online_count
## <dttm> <int>
## 1 2011-06-01 00:00:00 141
## 2 2011-09-01 00:00:00 157
## 3 2011-11-01 00:00:00 230
## 4 2014-06-01 00:00:00 939## Classes 'tbl_df', 'tbl' and 'data.frame': 4 obs. of 2 variables:
## $ orderdate : POSIXct, format: "2011-06-01" "2011-09-01" ...
## $ online_count: int 141 157 230 939And in this case they agree!
discuss February issues. and stuff.
look at each year sepraately as a diagnostic
Use the same pivot strategy on the corrected data.
difference between detective work with a graph and just print it out. “now I see what’s driving the hint.”
We have xx months when we add the month before and the month after the suspicious months. We don’t know whether the problem postings have been carried forward or backward. We check for and eliminate duplicates as well.
- Most of the Sales Reps’ orders are entered on a single day of the month, unique days = 1. It is possible that these are monthly recurring orders that get released on a given day of the month. If that is the case, what are the Sales Reps doing the rest of the month?
- ** ?? The lines with multiple days, unique_days > 1, have a noticeable higher number of orders, so_cnt, and associated so dollars.?? **
8.9 Correcting the order date for Sales Reps
8.9.1 Define a date correction function in R
This code does the date-correction work on the R side:
monthly_sales_rep_adjusted <- tbl(con, in_schema("sales", "salesorderheader")) %>%
filter(onlineorderflag == FALSE) %>%
select(orderdate, subtotal, onlineorderflag) %>%
group_by(orderdate) %>%
summarize(
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
mutate(
orderdate = as.Date(orderdate),
day = day(orderdate)
) %>%
collect() %>%
ungroup() %>%
mutate(
adjusted_orderdate = case_when(
day == 1L ~ orderdate -1,
TRUE ~ orderdate
),
year_month = floor_date(adjusted_orderdate, "month")
) %>%
group_by(year_month) %>%
summarize(
total_soh_dollars = round(sum(total_soh_dollars, na.rm = TRUE), 2),
soh_count = sum(soh_count)
) %>%
ungroup()Inspect:
## Classes 'tbl_df', 'tbl' and 'data.frame': 36 obs. of 3 variables:
## $ year_month : Date, format: "2011-05-01" "2011-06-01" ...
## $ total_soh_dollars: num 489329 1538408 1165897 844721 2324136 ...
## $ soh_count : int 38 75 60 40 90 63 40 79 64 37 ...## # A tibble: 12 x 3
## year_month total_soh_dollars soh_count
## <date> <dbl> <int>
## 1 2011-05-01 489329. 38
## 2 2011-06-01 1538408. 75
## 3 2011-07-01 1165897. 60
## 4 2011-08-01 844721 40
## 5 2011-09-01 2324136. 90
## 6 2011-10-01 1702945. 63
## 7 2011-11-01 713117. 40
## 8 2011-12-01 1900789. 79
## 9 2014-01-01 2738752. 175
## 10 2014-02-01 2207772. 94
## 11 2014-03-01 3321810. 180
## 12 2014-04-01 3416764. 1818.9.2 Define and store a PostgreSQL function to correct the date
The following code defines a function on the server side to correct the date:
dbExecute(
con,
"CREATE OR REPLACE FUNCTION so_adj_date(so_date timestamp, ONLINE_ORDER boolean) RETURNS timestamp AS $$
BEGIN
IF (ONLINE_ORDER) THEN
RETURN (SELECT so_date);
ELSE
RETURN(SELECT CASE WHEN EXTRACT(DAY FROM so_date) = 1
THEN so_date - '1 day'::interval
ELSE so_date
END
);
END IF;
END; $$
LANGUAGE PLPGSQL;
"
)## [1] 08.9.3 Use the PostgreSQL function
If you can do the heavy lifting on the database side, that’s good. R can do it, but it’s best for finding the issues.
monthly_sales_rep_adjusted_with_psql_function <- tbl(con, in_schema("sales", "salesorderheader")) %>%
select(orderdate, subtotal, onlineorderflag) %>%
mutate(
orderdate = as.Date(orderdate)) %>%
mutate(adjusted_orderdate = as.Date(so_adj_date(orderdate, onlineorderflag))) %>%
filter(onlineorderflag == FALSE) %>%
group_by(adjusted_orderdate) %>%
summarize(
total_soh_dollars = round(sum(subtotal, na.rm = TRUE), 2),
soh_count = n()
) %>%
collect() %>%
mutate( year_month = floor_date(adjusted_orderdate, "month")) %>%
group_by(year_month) %>%
ungroup() %>%
arrange(year_month)## # A tibble: 14 x 4
## adjusted_orderdate total_soh_dollars soh_count year_month
## <date> <dbl> <int> <date>
## 1 2011-05-31 489329. 38 2011-05-01
## 2 2011-06-30 1538408. 75 2011-06-01
## 3 2011-07-31 1165897. 60 2011-07-01
## 4 2011-08-31 844721 40 2011-08-01
## 5 2011-09-30 2324136. 90 2011-09-01
## 6 2011-10-31 1702945. 63 2011-10-01
## 7 2011-11-30 713117. 40 2011-11-01
## 8 2011-12-31 1900789. 79 2011-12-01
## 9 2014-01-28 1565. 2 2014-01-01
## 10 2014-01-29 2737188. 173 2014-01-01
## 11 2014-02-28 2207772. 94 2014-02-01
## 12 2014-03-30 7291. 2 2014-03-01
## 13 2014-03-31 3314519. 178 2014-03-01
## 14 2014-04-30 3416764. 181 2014-04-01There’s one minor difference between the two:
## [1] "Cols in y but not x: `adjusted_orderdate`. "8.9.4 Monthly Sales by Order Type with corrected dates – relative to a trend line
monthly_sales_rep_as_is <- monthly_sales_w_channel %>%
filter(onlineorderflag == "Sales Rep")
ggplot(
data = monthly_sales_rep_adjusted,
aes(x = year_month, y = soh_count)
) +
geom_line(alpha = .5) +
geom_smooth(se = FALSE) +
geom_smooth(
data = monthly_sales_rep_as_is, aes(
orderdate, soh_count
), color = "red", alpha = .5,
se = FALSE
) +
theme(plot.title = element_text(hjust = .5)) + # Center ggplot title
labs(
title = glue(
"Number of Sales per month using corrected dates\n",
"Counting Sales Order Header records"
),
x = paste0("Monthly - between ", min_soh_dt, " - ", max_soh_dt),
y = "Number of Sales Recorded"
)monthly_sales_rep_as_is <- monthly_sales_w_channel %>%
filter(onlineorderflag == "Sales Rep") %>%
mutate(orderdate = as.Date(floor_date(orderdate, unit = "month"))) %>%
group_by(orderdate) %>%
summarize(
total_soh_dollars = round(sum(total_soh_dollars, na.rm = TRUE), 2),
soh_count = sum(soh_count)
)
monthly_sales_rep_as_is %>%
filter(year(orderdate) %in% c(2011,2014))## # A tibble: 10 x 3
## orderdate total_soh_dollars soh_count
## <date> <dbl> <int>
## 1 2011-05-01 489329. 38
## 2 2011-07-01 1538408. 75
## 3 2011-08-01 2010618. 100
## 4 2011-10-01 4027080. 153
## 5 2011-12-01 713117. 40
## 6 2014-01-01 2738752. 175
## 7 2014-02-01 3231. 3
## 8 2014-03-01 5526352. 271
## 9 2014-04-01 1285. 2
## 10 2014-05-01 3415479. 179ggplot(
data = monthly_sales_rep_adjusted,
aes(x = year_month, y = soh_count)
) +
geom_line(alpha = .5 , color = "green") +
geom_point(alpha = .5 , color = "green") +
geom_point(
data = monthly_sales_rep_as_is, aes(
orderdate, soh_count), color = "red", alpha = .5) +
theme(plot.title = element_text(hjust = .5)) + # Center ggplot title
annotate(geom = "text", y = 250, x = as.Date("2011-06-01"),
label = "Orange dots: original data\nGreen dots: corrected data\nBrown dots: unchanged",
hjust = 0) +
labs(
title = glue(
"Number of Sales per Month"
),
subtitle = "Original and corrected amounts",
x = paste0("Monthly - between ", min_soh_dt, " - ", max_soh_dt),
y = "Number of Sales Recorded"
)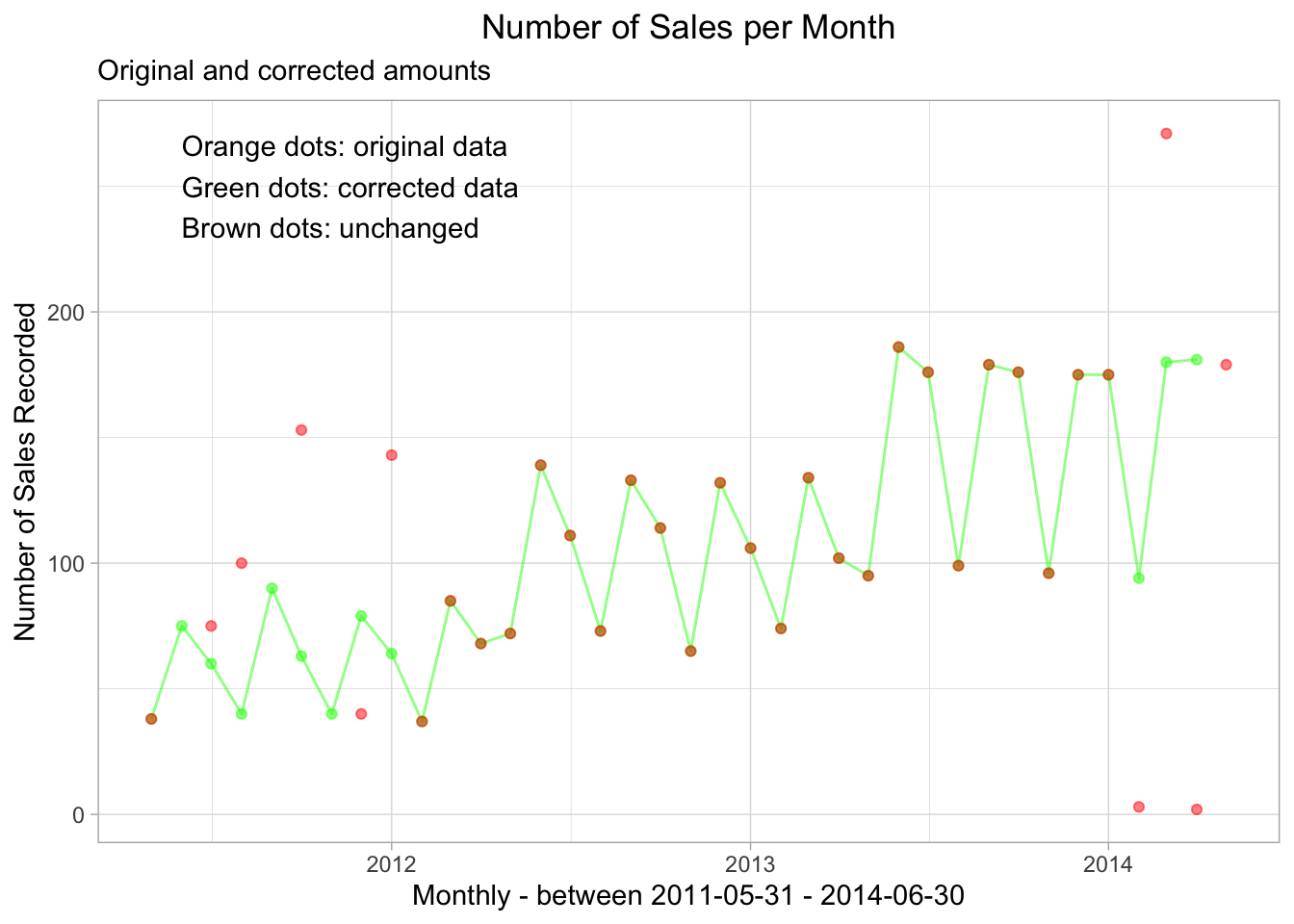
Figure 8.9: Comparing monthly_sales_rep_adjusted and monthly_sales_rep_as_is
mon_sales <- monthly_sales_rep_adjusted %>%
rename(orderdate = year_month)
sales_original_and_adjusted <- bind_rows(mon_sales, monthly_sales_rep_as_is, .id = "date_kind")Sales still seem to gyrate! We have found that sales rep sales data is often very strange.
8.10 Disconnect from the database and stop Docker
## Warning in connection_release(conn@ptr): Already disconnected