Chapter 11 Leveraging Database Views
This chapter demonstrates how to:
- Understand database views and their uses
- Unpack a database view to see what it’s doing
- Reproduce a database view with dplyr code
- Write an alternative to a view that provides more details
- Create a database view either for personal use or for submittal to your enterprise DBA
11.1 Setup our standard working environment
Use these libraries:
library(tidyverse)
library(DBI)
library(RPostgres)
library(connections)
library(glue)
require(knitr)
library(dbplyr)
library(sqlpetr)
library(bookdown)
library(lubridate)
library(gt)Connect to adventureworks:
# con <- connection_open( # use in an interactive session
con <- dbConnect( # use in other settings
RPostgres::Postgres(),
# without the previous and next lines, some functions fail with bigint data
# so change int64 to integer
bigint = "integer",
host = "localhost",
port = 5432,
user = "postgres",
password = "postgres",
dbname = "adventureworks"
)
dbExecute(con, "set search_path to sales;") # so that `dbListFields()` works## [1] 011.2 The role of database views
A database view is an SQL query that is stored in the database. Most views are used for data retrieval, since they usually denormalize the tables involved. Because they are standardized and well-understood, they can save you a lot of work and document a query that can serve as a model to build on.
11.2.1 Why database views are useful
Database views are useful for many reasons.
- Authoritative: database
viewsare typically written by the business application vendor or DBA, so they contain authoritative knowledge about the structure and intended use of the database. - Performance:
viewsare designed to gather data in an efficient way, using all the indexes in an efficient sequence and doing as much work on the database server as possible. - Abstraction:
viewsare abstractions or simplifications of complex queries that provide customary (useful) aggregations. Common examples would be monthly totals or aggregation of activity tied to one individual. - Reuse: a
viewputs commonly used code in one place where it can be used for many purposes by many people. If there is a change or a problem found in aview, it only needs to be fixed in one place, rather than having to change many places downstream. - Security: a view can give selective access to someone who does not have access to underlying tables or columns.
- Provenance:
viewsstandardize data provenance. For example, theAdventureWorksdatabase all of them are named in a consistent way that suggests the underlying tables that they query. And they all start with a v.
The bottom line is that views can save you a lot of work.
11.2.2 Rely on – and be critical of – views
Because they represent a commonly used view of the database, it might seem like a view is always right. Even though they are conventional and authorized, they may still need verification or auditing, especially when used for a purpose other than the original intent. They can guide you toward what you need from the database but they could also mislead because they are easy to use and available. People may forget why a specific view exists and who is using it. Therefore any given view might be a forgotten vestige. part of a production data pipeline or a priceless nugget of insight. Who knows? Consider the view’s owner, schema, whether it’s a materialized index view or not, if it has a trigger and what the likely intention was behind the view.
11.3 Unpacking the elements of a view in the Tidyverse
Since a view is in some ways just like an ordinary table, we can use familiar tools in the same way as they are used on a database table. For example, the simplest way of getting a list of columns in a view is the same as it is for a regular table:
## [1] "salespersonid" "fullname" "jobtitle" "salesterritory"
## [5] "salestotal" "fiscalyear"11.3.1 Use a view just like any other table
From a retrieval perspective a database view is just like any other table. Using a view to retrieve data from the database will be completely standard across all flavors of SQL.
v_salesperson_sales_by_fiscal_years_data <-
tbl(con, in_schema("sales","vsalespersonsalesbyfiscalyearsdata")) %>%
collect()
str(v_salesperson_sales_by_fiscal_years_data)## Classes 'tbl_df', 'tbl' and 'data.frame': 48 obs. of 6 variables:
## $ salespersonid : int 275 275 275 275 276 276 276 276 277 277 ...
## $ fullname : chr "Michael G Blythe" "Michael G Blythe" "Michael G Blythe" "Michael G Blythe" ...
## $ jobtitle : chr "Sales Representative" "Sales Representative" "Sales Representative" "Sales Representative" ...
## $ salesterritory: chr "Northeast" "Northeast" "Northeast" "Northeast" ...
## $ salestotal : num 63763 2399593 3765459 3065088 5476 ...
## $ fiscalyear : num 2011 2012 2013 2014 2011 ...As we will see, our sample view, vsalespersonsalesbyfiscalyearsdata joins 5 different tables. We can assume that subsetting or calculation on any of the columns in the component tables will happen behind the scenes, on the database side, and done correctly. For example, the following query filters on a column that exists in only one of the view’s component tables.
tbl(con, in_schema("sales","vsalespersonsalesbyfiscalyearsdata")) %>%
count(salesterritory, fiscalyear) %>%
collect() %>% # ---- pull data here ---- #
pivot_wider(names_from = fiscalyear, values_from = n, names_prefix = "FY_")## # A tibble: 10 x 5
## # Groups: salesterritory [10]
## salesterritory FY_2014 FY_2011 FY_2013 FY_2012
## <chr> <int> <int> <int> <int>
## 1 Southwest 2 2 2 2
## 2 Northeast 1 1 1 1
## 3 Southeast 1 1 1 1
## 4 France 1 NA 1 1
## 5 Canada 2 2 2 2
## 6 United Kingdom 1 NA 1 1
## 7 Northwest 3 2 3 2
## 8 Central 1 1 1 1
## 9 Australia 1 NA 1 NA
## 10 Germany 1 NA 1 NAAlthough finding out what a view does behind the scenes requires that you use functions that are not standard, doing so has several general purposes:
- It is satisfying to know what’s going on behind the scenes.
- Specific elements or components of a
viewmight be worth plagiarizing or incorporating in our queries. - It is necessary to understand the mechanics of a
viewif we are going to build on what it does or intend to extend or modify it.
11.3.2 SQL source code
Functions for inspecting a view itself are not part of the ANSI standard, so they will be database-specific. Here is the code to retrieve a PostgreSQL view (using the pg_get_viewdef function):
view_definition <- dbGetQuery(con, "select
pg_get_viewdef('sales.vsalespersonsalesbyfiscalyearsdata',
true)")The PostgreSQL pg_get_viewdef function returns a data frame with one column named pg_get_viewdef and one row. To properly view its contents, the \n character strings need to be turned into new-lines.
## SELECT granular.salespersonid,
## granular.fullname,
## granular.jobtitle,
## granular.salesterritory,
## sum(granular.subtotal) AS salestotal,
## granular.fiscalyear
## FROM ( SELECT soh.salespersonid,
## ((p.firstname::text || ' '::text) || COALESCE(p.middlename::text || ' '::text, ''::text)) || p.lastname::text AS fullname,
## e.jobtitle,
## st.name AS salesterritory,
## soh.subtotal,
## date_part('year'::text, soh.orderdate + '6 mons'::interval) AS fiscalyear
## FROM salesperson sp
## JOIN salesorderheader soh ON sp.businessentityid = soh.salespersonid
## JOIN salesterritory st ON sp.territoryid = st.territoryid
## JOIN humanresources.employee e ON soh.salespersonid = e.businessentityid
## JOIN person.person p ON p.businessentityid = sp.businessentityid) granular
## GROUP BY granular.salespersonid, granular.fullname, granular.jobtitle, granular.salesterritory, granular.fiscalyear;Even if you don’t intend to become completely fluent in SQL, it’s useful to study as much of it as possible. Studying the SQL in a view is particularly useful to:
- Test your understanding of the database structure, elements, and usage
- Extend what’s already been done to extract useful data from the database
11.3.3 The ERD as context for SQL code
A database Entity Relationship Diagram (ERD) is very helpful in making sense of the SQL in a view. The ERD for AdventureWorks is here. If a published ERD is not available, a tool like the PostgreSQL pg_modeler is capable of generating an ERD (or at least describing the portion of the database that is visible to you).
{kind=link}
11.3.4 Selecting relevant tables and columns
Before bginning to write code, it can be helpful to actually mark up the ERD to identify the specific tables that are involved in the view you are going to reproduce.
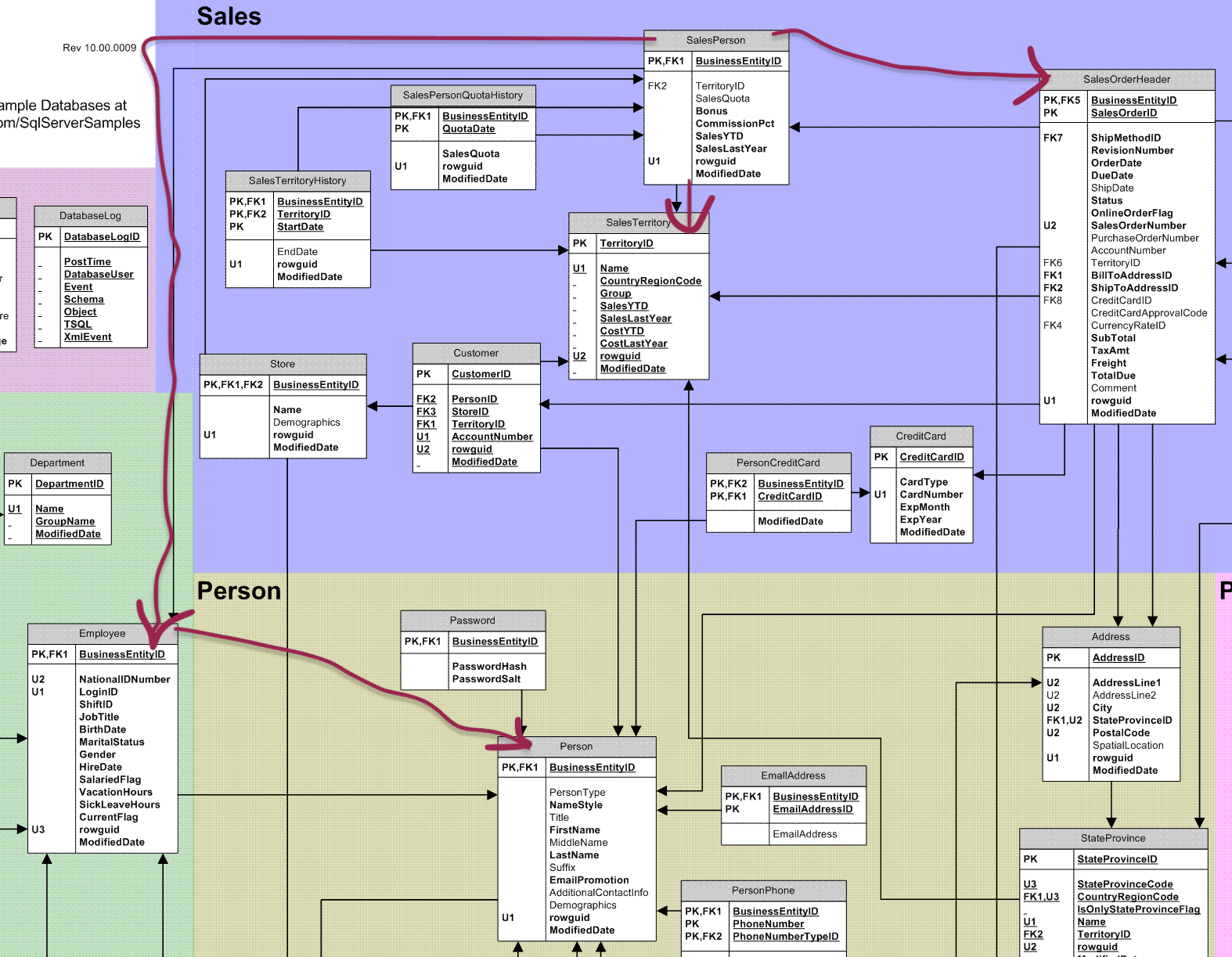
Define each table that is involved and identify the columns that will be needed from that table. The sales.vsalespersonsalesbyfiscalyearsdata view joins data from five different tables:
- sales_order_header
- sales_territory
- sales_person
- employee
- person
For each of the tables in the view, we select the columns that appear in the sales.vsalespersonsalesbyfiscalyearsdata. Selecting columns in this way prevents joins that dbplyr would make automatically based on common column names, such as rowguid and ModifiedDate columns, which appear in almost all AdventureWorks tables. In the following code we follow the convention that any column that we change or create on the fly uses a snake case naming convention.
sales_order_header <- tbl(con, in_schema("sales", "salesorderheader")) %>%
select(orderdate, salespersonid, subtotal)
sales_territory <- tbl(con, in_schema("sales", "salesterritory")) %>%
select(territoryid, territory_name = name)
sales_person <- tbl(con, in_schema("sales", "salesperson")) %>%
select(businessentityid, territoryid)
employee <- tbl(con, in_schema("humanresources", "employee")) %>%
select(businessentityid, jobtitle)In addition to selecting rows as shown in the previous statements, mutate and other functions help us replicate code in the view such as:
((p.firstname::text || ' '::text) ||
COALESCE(p.middlename::text || ' '::text,
''::text)) || p.lastname::text AS fullnameThe following dplyr code pastes the first, middle and last names together to make full_name:
person <- tbl(con, in_schema("person", "person")) %>%
mutate(full_name = paste(firstname, middlename, lastname)) %>%
select(businessentityid, full_name)Double-check on the names that are defined in each tbl object. The following function will show the names of columns in the tables we’ve defined:
Verify the names selected:
## [1] "orderdate" "salespersonid" "subtotal"## [1] "territoryid" "territory_name"## [1] "businessentityid" "territoryid"## [1] "businessentityid" "jobtitle"## [1] "businessentityid" "full_name"11.3.5 Join the tables together
First, join and download all of the data pertaining to a person. Notice that since each of these 4 tables contain businessentityid, dplyr will join them all on that common column automatically. And since we know that all of these tables are small, we don’t mind a query that joins and downloads all the data.
salesperson_info <- sales_person %>%
left_join(employee) %>%
left_join(person) %>%
left_join(sales_territory) %>%
collect()## Joining, by = "businessentityid"
## Joining, by = "businessentityid"## Joining, by = "territoryid"## Classes 'tbl_df', 'tbl' and 'data.frame': 17 obs. of 5 variables:
## $ businessentityid: int 274 275 276 277 278 279 280 281 282 283 ...
## $ territoryid : int NA 2 4 3 6 5 1 4 6 1 ...
## $ jobtitle : chr "North American Sales Manager" "Sales Representative" "Sales Representative" "Sales Representative" ...
## $ full_name : chr "Stephen Y Jiang" "Michael G Blythe" "Linda C Mitchell" "Jillian Carson" ...
## $ territory_name : chr NA "Northeast" "Southwest" "Central" ...The one part of the view that we haven’t replicated is:
date_part('year'::text, soh.orderdate
+ '6 mons'::interval) AS fiscalyear
The lubridate package makes it very easy to convert orderdate to fiscal_year. Doing that same conversion without lubridate (e.g., only dplyr and ANSI-STANDARD SQL) is harder. Therefore we just pull the data from the server after the left_join and do the rest of the job on the R side. Note that this query doesn’t correct the problematic entry dates that we explored in the chapter on Asking Business Questions From a Single Table. That will collapse many rows into a much smaller table. We know from our previous investigation that Sales Rep into sales are recorded more or less once a month. Therefore most of the crunching in this query happens on the database server side.
sales_data_fiscal_year <- sales_person %>%
left_join(sales_order_header, by = c("businessentityid" = "salespersonid")) %>%
group_by(businessentityid, orderdate) %>%
summarize(sales_total = sum(subtotal, na.rm = TRUE)) %>%
mutate(
orderdate = as.Date(orderdate),
day = day(orderdate)
) %>%
collect() %>% # ---- pull data here ---- #
mutate(
fiscal_year = year(orderdate %m+% months(6))
) %>%
ungroup() %>%
group_by(businessentityid, fiscal_year) %>%
summarize(sales_total = sum(sales_total, na.rm = FALSE)) %>%
ungroup()Put the two parts together: sales_data_fiscal_year and person_info to yield the final query.
salesperson_sales_by_fiscal_years_dplyr <- sales_data_fiscal_year %>%
left_join(salesperson_info) %>%
filter(!is.na(territoryid))## Joining, by = "businessentityid"Notice that we’re dropping the Sales Managers who appear in the salesperson_info data frame because they don’t have a territoryid.
11.4 Compare the official view and the dplyr output
Use pivot_wider to make it easier to compare the native view to our dplyr replicate.
salesperson_sales_by_fiscal_years_dplyr %>%
select(-jobtitle, -businessentityid, -territoryid) %>%
pivot_wider(names_from = fiscal_year, values_from = sales_total,
values_fill = list(sales_total = 0)) %>%
arrange(territory_name, full_name) %>%
filter(territory_name == "Canada")## # A tibble: 2 x 6
## full_name territory_name `2011` `2012` `2013` `2014`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Garrett R Vargas Canada 9109. 1254087. 1179531. 1166720.
## 2 José Edvaldo Saraiva Canada 106252. 2171995. 1388793. 2259378.v_salesperson_sales_by_fiscal_years_data %>%
select(-jobtitle, -salespersonid) %>%
pivot_wider(names_from = fiscalyear, values_from = salestotal,
values_fill = list(salestotal = 0)) %>%
arrange(salesterritory, fullname) %>%
filter(salesterritory == "Canada")## # A tibble: 2 x 6
## fullname salesterritory `2011` `2012` `2013` `2014`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Garrett R Vargas Canada 9109. 1254087. 1179531. 1166720.
## 2 José Edvaldo Saraiva Canada 106252. 2171995. 1388793. 2259378.The yearly totals match exactly. The column names don’t match up, because we are using snake case convention for derived elements.
11.5 Revise the view to summarize by quarter not fiscal year
To summarize sales data by SAles Rep and quarter requires the %m+% infix operator from lubridate. The interleaved comments in the query below has hints that explain it. The totals in this revised query are off by a rounding error from the totals shown above in the fiscal year summaries.
tbl(con, in_schema("sales", "salesorderheader")) %>%
group_by(salespersonid, orderdate) %>%
summarize(subtotal = sum(subtotal, na.rm = TRUE), digits = 0) %>%
collect() %>% # ---- pull data here ---- #
# Adding 6 months to orderdate requires a lubridate function
mutate(orderdate = as.Date(orderdate) %m+% months(6),
year = year(orderdate),
quarter = quarter(orderdate)) %>%
ungroup() %>%
group_by(salespersonid, year, quarter) %>%
summarize(subtotal = round(sum(subtotal, na.rm = TRUE), digits = 0)) %>%
ungroup() %>%
# Join with the person information previously gathered
left_join(salesperson_info, by = c("salespersonid" = "businessentityid")) %>%
filter(territory_name == "Canada") %>%
# Pivot to make it easier to see what's going on
pivot_wider(names_from = quarter, values_from = subtotal,
values_fill = list(Q1 = 0, Q2 = 0, Q3 = 0, Q4 = 0), names_prefix = "Q", id_cols = full_name:year) %>%
select(`Name` = full_name, year, Q1, Q2, Q3, Q4) %>%
mutate(`Year Total` = Q1 + Q2 + Q3 + Q4) %>%
head(., n = 10) %>%
gt() %>%
fmt_number(use_seps = TRUE, decimals = 0, columns = vars(Q1,Q2, Q3, Q4, `Year Total`))| Name | year | Q1 | Q2 | Q3 | Q4 | Year Total |
|---|---|---|---|---|---|---|
| Garrett R Vargas | 2011 | NA | NA | NA | 9,109 | NA |
| Garrett R Vargas | 2012 | 233,696 | 257,287 | 410,518 | 352,587 | 1,254,088 |
| Garrett R Vargas | 2013 | 316,818 | 203,647 | 291,333 | 367,732 | 1,179,530 |
| Garrett R Vargas | 2014 | 393,788 | 336,984 | 290,536 | 145,413 | 1,166,721 |
| José Edvaldo Saraiva | 2011 | NA | NA | NA | 106,252 | NA |
| José Edvaldo Saraiva | 2012 | 521,794 | 546,962 | 795,861 | 307,379 | 2,171,996 |
| José Edvaldo Saraiva | 2013 | 408,415 | 324,062 | 231,991 | 424,326 | 1,388,794 |
| José Edvaldo Saraiva | 2014 | 748,430 | 466,137 | 618,832 | 425,979 | 2,259,378 |